Review
- 2023-02-12 15:42
解释器是如何解释执行字节码的
一、Introduction #
字节码的解释执行在编译流水线中的位置你可以参看下图:
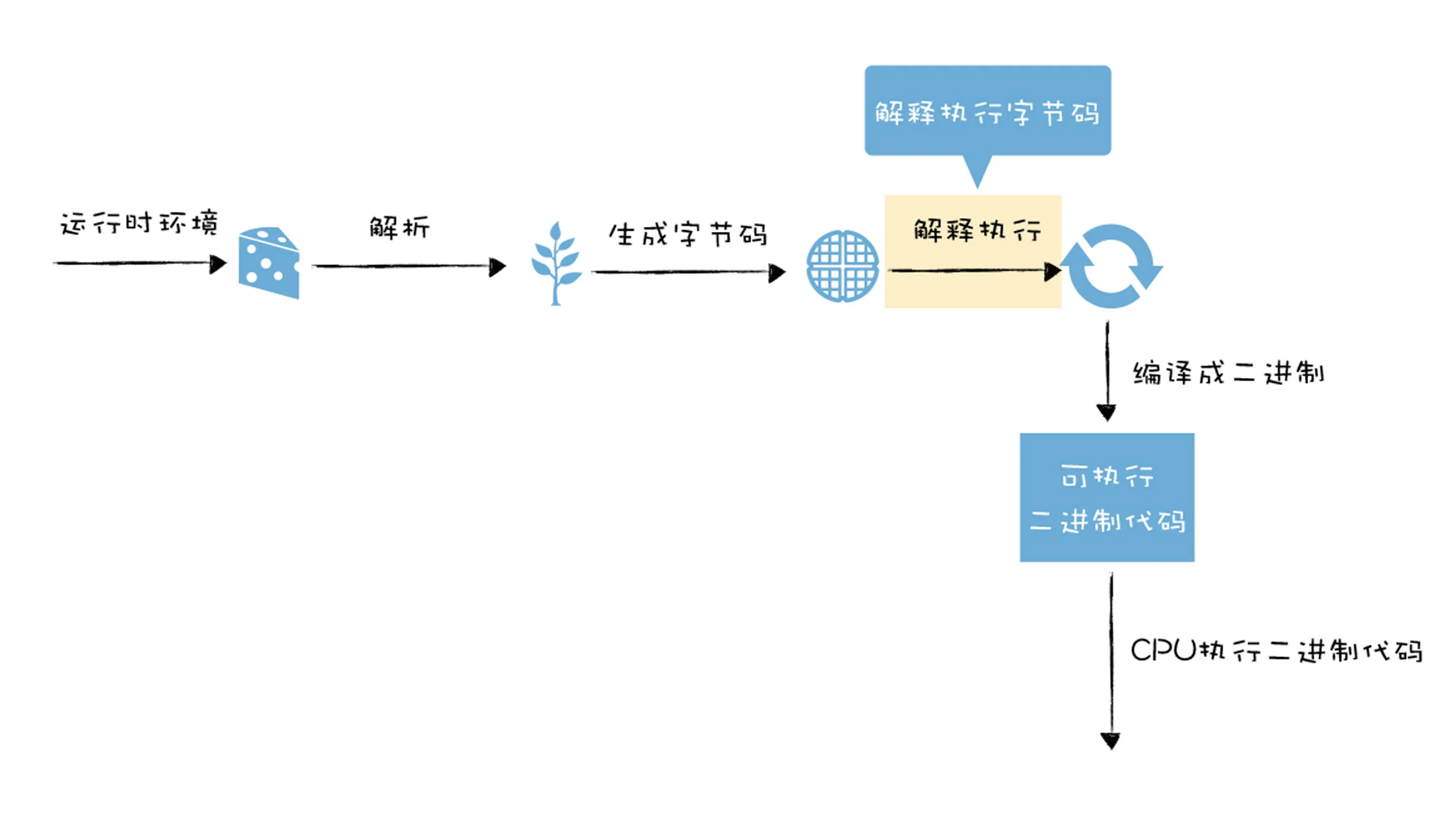
如何生成字节码? #
当 V8 执行一段 JavaScript 代码时,会先对 JavaScript 代码进行解析 (Parser),并生成为 AST 和作用域信息,之后 AST 和作用域信息被输入到一个称为 Ignition 的解释器中,并将其转化为字节码,之后字节码再由 Ignition 解释器来解释执行。
// test.js
function add(x, y) {
var z = x+y
return z
}
console.log(add(1, 2))V8 首先会将函数的源码解析为 AST,这一步由解析器 (Parser) 完成
dk --print-ast test.js[generating bytecode for function: add]
--- AST ---
FUNC at 12
. KIND 0
. LITERAL ID 1
. SUSPEND COUNT 0
. NAME "add"
. PARAMS
. . VAR (0x7fa7b781ae70) (mode = VAR, assigned = false) "x"
. . VAR (0x7fa7b781aef0) (mode = VAR, assigned = false) "y"
. DECLS
. . VARIABLE (0x7fa7b781ae70) (mode = VAR, assigned = false) "x"
. . VARIABLE (0x7fa7b781aef0) (mode = VAR, assigned = false) "y"
. . VARIABLE (0x7fa7b781af70) (mode = VAR, assigned = false) "z"
. BLOCK NOCOMPLETIONS at -1
. . EXPRESSION STATEMENT at 31
. . . INIT at 31
. . . . VAR PROXY local[0] (0x7fa7b781af70) (mode = VAR, assigned = false) "z"
. . . . ADD at 32
. . . . . VAR PROXY parameter[0] (0x7fa7b781ae70) (mode = VAR, assigned = false) "x"
. . . . . VAR PROXY parameter[1] (0x7fa7b781aef0) (mode = VAR, assigned = false) "y"
. RETURN at 37
. . VAR PROXY local[0] (0x7fa7b781af70) (mode = VAR, assigned = false) "z"
3将其图形化:
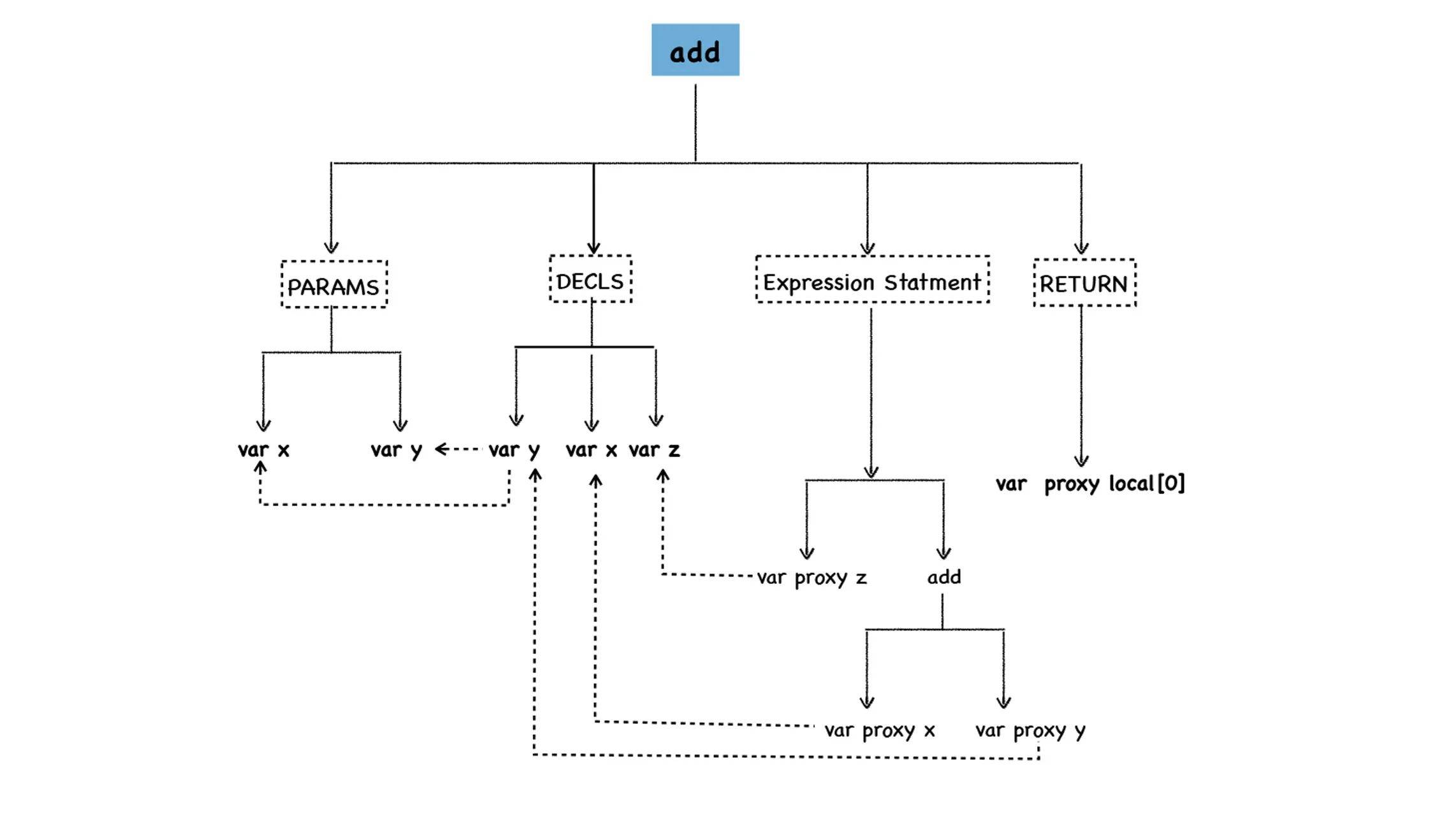
从图中可以看出,函数的字面量被解析为 AST 树的形态,这个函数主要拆分成四部分。
- 第一部分为参数声明 (PARAMS),参数声明中包括了所有的参数,在这里主要是参数 x 和参数 y,你可以在函数体中使用 arguments 来使用对应的参数。
- 第二部分是变量声明节点 (DECLS),参数部分你可以使用 arguments 来调用,同样,你也可以将这些参数作为变量来直接使用,这体现在 DECLS 节点下面也出现了变量 x 和变量 y,除了可以直接使用 x 和 y 之外,我们还有一个 z 变量也在 DECLS 节点下。注意看,在上面生成的 AST 数据中,参数声明节点中的 x 和变量声明节点中的 x 的地址是相同的,都是 0x7fa7b781ae70,同样 y 也是相同的,都是 0x7fa7b781aef0,这说明它们指向的是同一块数据。
- 第三部分是 x+y 的表达式节点,我们可以看到,节点 add 下面使用了
var proxy x和var proxy y的语法,它们指向了实际 x 和 y 的值。 - 第四部分是 RETURN 节点,它指向了 z 的值,在这里是 local[0]。
V8 在生成 AST 的同时,还生成了 add 函数的作用域,你可以使用 dk –-print-scopes test.js 命令来查看:
Global scope:
function add (x, y) { // (0x7fa6fb02f620) (12, 47)
// will be compiled
// NormalFunction
// 1 stack slots
// local vars:
VAR x; // (0x7fa6fb02f870) parameter[0], never assigned
VAR z; // (0x7fa6fb02f970) local[0], never assigned
VAR y; // (0x7fa6fb02f8f0) parameter[1], never assigned
}作用域中的变量都是未使用的,默认值都是 undefined,在执行阶段,作用域中的变量会指向堆和栈中相应的数据,作用域和实际数据的关系如下图所示:
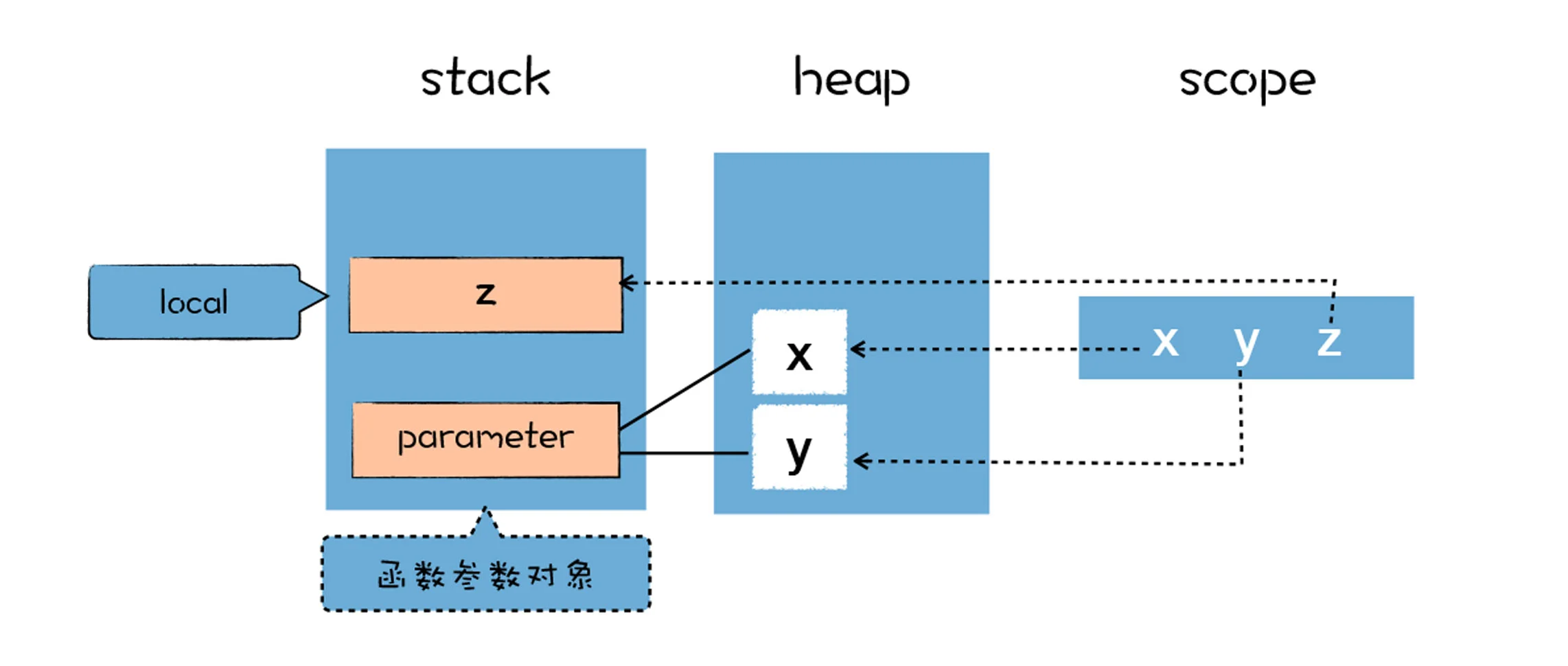
在解析期间,所有函数体中声明的变量和函数参数,都被放进作用域中,如果是普通变量,那么默认值是 undefined,如果是函数声明,那么将指向实际的函数对象。
一旦生成了作用域和 AST,V8 就可以依据它们来生成字节码了。AST 之后会被作为输入传到字节码生成器 (BytecodeGenerator),这是 Ignition 解释器中的一部分,用于生成以函数为单位的字节码。你可以通过 dk –-print-bytecode test.js 命令查看生成的字节码。
[generated bytecode for function: add (0x25ff0025a72d <SharedFunctionInfo add>)]
Bytecode length: 7
Parameter count 3
Register count 1
Frame size 8
Bytecode age: 0
0x25ff0025a8d6 @ 0 : 0b 04 Ldar a1
0x25ff0025a8d8 @ 2 : 38 03 00 Add a0, [0]
0x25ff0025a8db @ 5 : c4 Star0
0x25ff0025a8dc @ 6 : a9 Return
Constant pool (size = 0)
Handler Table (size = 0)
Source Position Table (size = 0)可以看到,生成的字节码提示了“Parameter count 3”,这是说这里有三个参数,包括了显式地传入了 x 和 y,还有一个隐式地传入了 this。下面是字节码的详细信息:
StackCheck
Ldar a1
Add a0, [0]
Star r0
LdaSmi [2]
Star r1
Ldar r0
Return将 JavaScript 函数转换为字节码之后,我们看到只有 8 行,接下来我们的任务就是要分析这 8 行字节码是怎么工作的,理解了这 8 行字节码是怎么工作的,就可以学习其他字节码的工作方式了。
理解字节码:解释器的架构设计 #
通过上面的一段字节码我们可以看到,字节码似乎和汇编代码有点像,这些字节码看起来似乎难以理解,但实际上它们非常简单,每一行表示一个特定的功能,把这些功能拼凑在一起就构成完整的程序。
V8字节码指令集 bytecodes.h
阅读汇编代码,需要先理解 CPU 的体系架构,然后再分析特定汇编指令的具体含义,同样,要了解怎么阅读字节码,我们就需要理解 V8 解释器的整体设计架构,然后再来分析特定的字节码指令的含义。
因为解释器就是模拟物理机器来执行字节码的,比如可以实现如取指令、解析指令、执行指令、存储数据等,所以解释器的执行架构和 CPU 处理机器代码的架构类似。
通常有两种类型的解释器,基于栈 (Stack-based) 和 基于寄存器 (Register-based),基于栈的解释器使用栈来保存函数参数、中间运算结果、变量等,基于寄存器的虚拟机则支持寄存器的指令操作,使用寄存器来保存参数、中间计算结果。
通常,基于栈的虚拟机也定义了少量的寄存器,基于寄存器的虚拟机也有堆栈,其区别体现在它们提供的指令集体系。
大多数解释器都是基于栈的,比如 Java 虚拟机,.Net 虚拟机,还有早期的 V8 虚拟机。基于栈的虚拟机在处理函数调用、解决递归问题和切换上下文时简单明快。
而现在的 ==V8 虚拟机则采用了基于寄存器的设计,它将一些中间数据保存到寄存器中==,了解这点对于我们分析字节码的执行过程非常重要。
基于寄存器的解释器架构
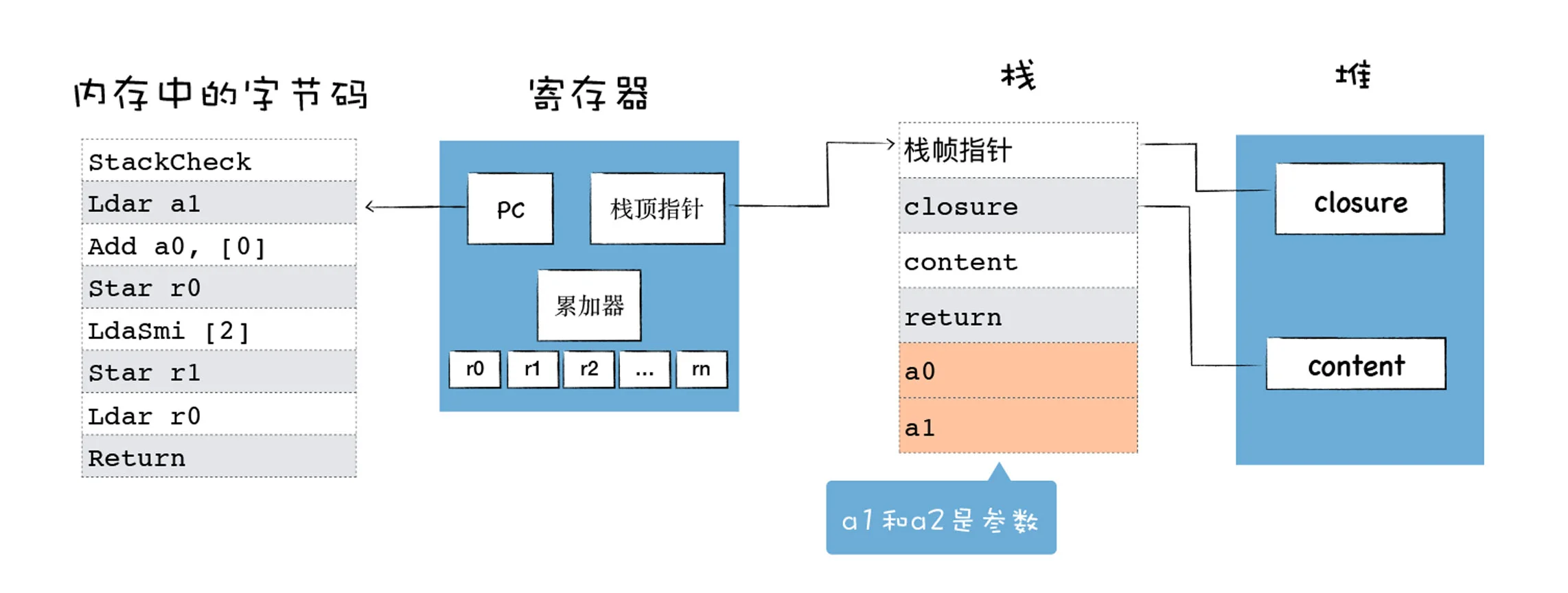
解释器执行时主要有四个模块,内存中的字节码、寄存器、栈、堆。
- 使用内存中的一块区域来存放字节码;
- 使用了通用寄存器 r0,r1,r2,…… 这些寄存器用来存放一些中间数据;
- PC 寄存器用来指向下一条要执行的字节码;
- 栈顶寄存器用来指向当前的栈顶的位置。
注意这里的累加器,它是一个非常特殊的寄存器,用来保存中间的结果。
完整分析一段字节码 #
StackCheck
Ldar a1
Add a0, [0]
Star r0
LdaSmi [2]
Star r1
Ldar r0
Return执行这段代码时,整体的状态如下图所示:
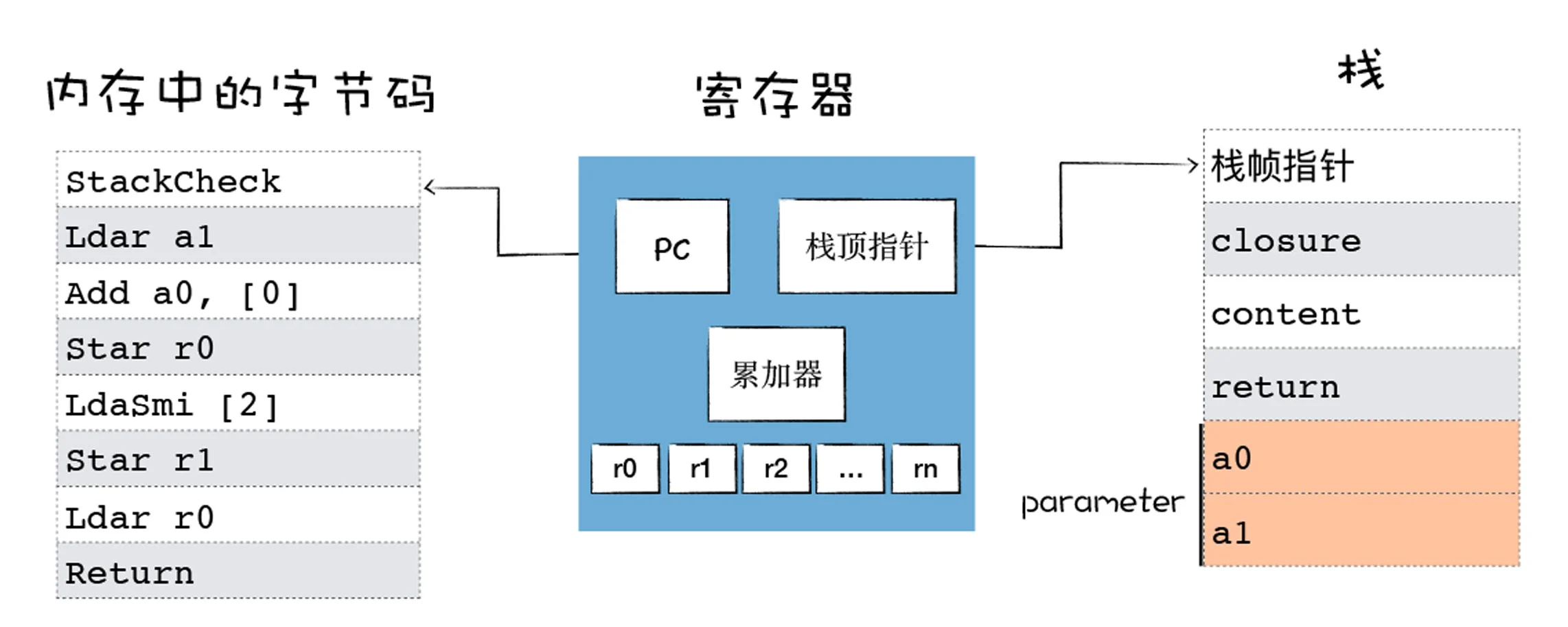
- 参数对象 parameter 保存在栈中,包含了 a0 和 a1 两个值,在上面的代码中,这两个值分别是 1 和 2;
- PC 寄存器指向了第一个字节码 StackCheck,我们知道,V8 在执行一个函数之前,会判断栈是否会溢出,这里的 StackCheck 字节码指令就是检查栈是否达到了溢出的上限,如果栈增长超过某个阈值,我们将中止该函数的执行并抛出一个 RangeError,表示栈已溢出。
然后继续执行下一条字节码,Ldar a1,这是将 a1 寄存器中的参数值加载到累加器中,这时候第一个参数就保存到累加器中了。
接下来执行加法操作,Add a0, [0],因为 a0 是第一个寄存器,存放了第一个参数,Add a0 就是将第一个寄存器中的值和累加器中的值相加,也就是将累加器中的 2 和通用寄存器中 a0 中的 1 进行相加,同时将相加后的结果 3 保存到累加器中。
现在累加器中就保存了相加后的结果,然后执行第四段字节码,Star r0,这是将累加器中的值,也就是 1+2 的结果 3 保存到寄存器 r0 中,那么现在寄存器 r0 中的值就是 3 了。
然后将常数 2 加载到累加器中,又将累加器中的 2 加载到寄存器 r1 中,我们发现这里两段代码可能没实际的用途,不过 V8 生成的字节码就是这样。
接下来 V8 将寄存器 r0 中的值加载到累加器中,然后执行最后一句 Return 指令,Return 指令会中断当前函数的执行,并将累加器中的值作为返回值。
这样 V8 就执行完成了 add 函数。
实战 #
// test.js
function foo() {
var d = 20
return function inner(a, b) {
const c = a + b + d
return c
}
}
const f = foo()
f(1,2)dk --print-bytecode test.js[generated bytecode for function: inner (0x1b970025a97d <SharedFunctionInfo inner>)]
Bytecode length: 13
Parameter count 3
Register count 2
Frame size 16
Bytecode age: 0
0x1b970025aa62 @ 0 : 0b 04 Ldar a1
0x1b970025aa64 @ 2 : 38 03 00 Add a0, [0]
0x1b970025aa67 @ 5 : c3 Star1
0x1b970025aa68 @ 6 : 17 02 LdaImmutableCurrentContextSlot [2]
0x1b970025aa6a @ 8 : 38 f9 01 Add r1, [1]
0x1b970025aa6d @ 11 : c4 Star0
0x1b970025aa6e @ 12 : a9 Return
Constant pool (size = 0)
Handler Table (size = 0)
Source Position Table (size = 0)